
The Case For Short AI Timelines
The Other Side of the Ledger


Last week, we reviewed the best inside view arguments that timelines to AGI may be longer than 10 years. This week, we will review the best arguments for short timelines: <10 years and perhaps much sooner. Again, these reflections are our “inside-view” about why AI timelines might take a long time rather than appealing to the market, forecasters, etc.
1. AGI is “Achieved” on Short Tasks
The best argument for AGI soon is that we have something pretty close to AGI in capabilities right now on simple QA questions. o3 is getting 25% on Frontier Math problems, 36% of Humanity’s Last Exam, and near human expert levels of 90% on Google-Proof Graduate Questions. All of these tests measure brutally hard PhD and beyond level performance in a wide variety of academic fields. We are quite confident no human on earth exceeds all three of these scores. Therefore, it is fair to say that AGI has pretty much been achieved on simple QA benchmarks.
What is left to achieve AGI? Well, it’s mostly long-term planning, executive function, agency, etc., to turn that raw intelligence into useful labor. That is not much left to achieve! It wouldn’t be surprising if one small tweak—scaling, RL, or something—adds agency, and then AGI is here.
2. Agency Seems On Trend
Of course, how close we are to AGI depends on how hard agency is to add to LLMs. Maybe agency is very difficult to achieve. For example, Epoch argues that agency may be difficult because it is a very fundamental trait in animals, baked in by evolution millions of years ago. Since it is so fundamental in humans, there is not a lot of text data about how to learn it, nor is there a clear way we know to ‘teach’ agency in the same way we teach math and code.
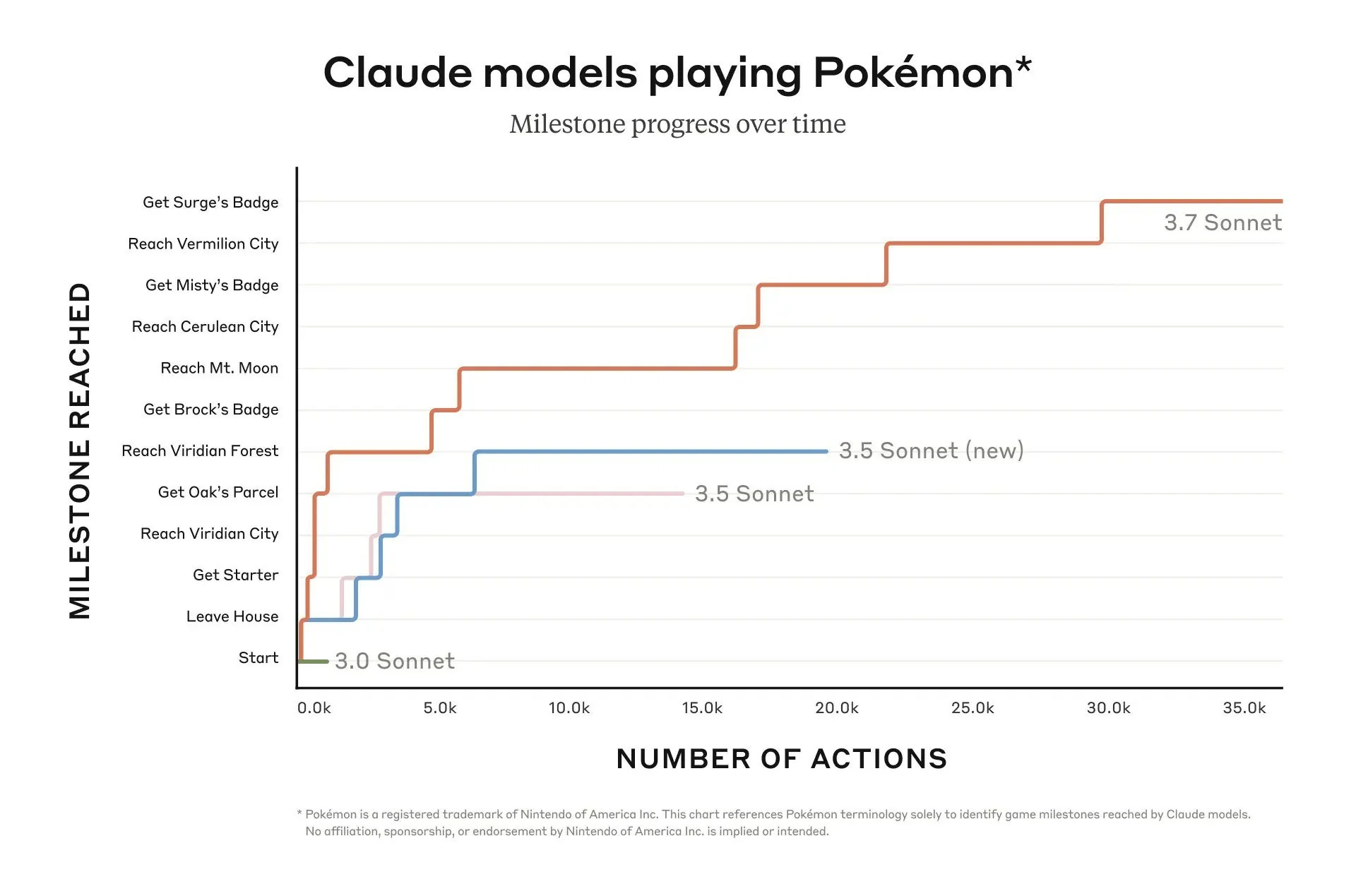
Nevertheless, LLMs seem to be getting better at agency quite quickly. For example, METR estimates that the task horizon at which models can effectively operate on has doubled roughly every 200 days for the last few years. Moreover, Claude plays Pokemon has seen substantial improvements from Claude 3 to Claude 3.7. While both benchmarks show there is still quite a ways to go on long-term planning/agency, the trend on both shows that we are heading in the right direction with general post-training methods. If we naively extrapolate the trends, models achieving human-level performance on 24-hour tasks is about 4 years out. That is well within the frame of short AI timelines!

3. There Seems to be a lot of Low-Hanging Fruit Left in ML
Since the release of GPT-4, we have seen a very large increase in various benchmarks. Most of the returns have come from simple algorithmic improvements like better RLHF, better character training, RL on verifiable rewards, etc. None of these are ‘genius’ ideas. ML researchers are mostly just doing obvious things, and this seems to be working. We’ve only picked this low-hanging fruit for about 2-4 years, so it would be pretty surprising if there is not a lot left to pick up. Even just normal ML progress should see a lot of progress by picking up these simple ideas.
4. The Death of Pre-Training May Be Overstated
GPT 4.5 on release was seen by many as a disappointment and a sign that the era of pre-training scaling was ending. But we think this conclusion, while it has some truth to it, is a bit overstated. As noted by Epoch, GPT 4.5’s performance on GPQA was above trend for pre-training scaling laws, and many people, like Tyler Cowen, are noting that GPT 4.5 is funnier, smarter, a better writer, and has more world knowledge. These general gains, while not that useful to many end-users, do still indicate that scaling generally boosts intelligence. These general gains will likely lead to downstream boosts when adding reasoning, agency RL, etc. Of course, this is not a sure thing, but I do think pre-training on top will continue to be important for years to come.
5. Unusually High Investment Will Occur In the Next 5-10 Years
OpenAI hit 4 billion in revenue this year and has seen its valuation balloon to $350 billion. Moreover, demand for AI is increasing, particularly from enterprise where usage increased from $600 million to $4.6 billion. Additionally, AI applications are turning up from left to right from coding assistants like Cursor to agents like Manus. Accordingly, demand for AI is high and rising. We expect another large jump in revenue for OpenAI in 2026 as well.
This money flowing into AI will be aggressively reinvested into R&D, creating a one-time, massive acceleration in AI R&D over the next 5-10 years. Note that this investment growth cannot go on forever. Once you start investing a significant share of GDP in AI R&D, it becomes hard to increase that investment. This creates a narrow time window where exponential investment growth can drive exponential capability gains, followed by a natural ceiling once AI becomes a mature economic sector with more constrained growth potential.
Conclusion
We have now reviewed the various arguments for and against short timelines. Our main takeaway is that AGI in the next 5-10 years is plausible! It’s certainly not a sure thing for the reasons we mentioned in the previous post, but even a 30% chance of AGI in the next few years is striking. One interesting result of our analysis of the arguments is that AGI is likely to be soon (<5 years) or in decades, with little probability mass on the intervening years. If LLMs, with some tweaks, take us to AGI, then we could see huge progress even in the next 3 years. If LLMs don’t take us to AGI by 2035, then we will be back in the wilderness.
 | A guest post by
|