
The Case For Longer AI Timelines
A review of some arguments


Epistemic Status: Low
In this article, we are going to present the strongest arguments we have for why artificial intelligence progress might take longer than some expect, e.g. 10+ years. These reflections are our “inside-view” about why AI timelines might take a long time rather than appealing to the market, forecasters, etc. In a few weeks, we’ll follow up with a companion piece that discusses the best reasons for anticipating shorter AI timelines.
1. Pre-training May Be Running Out
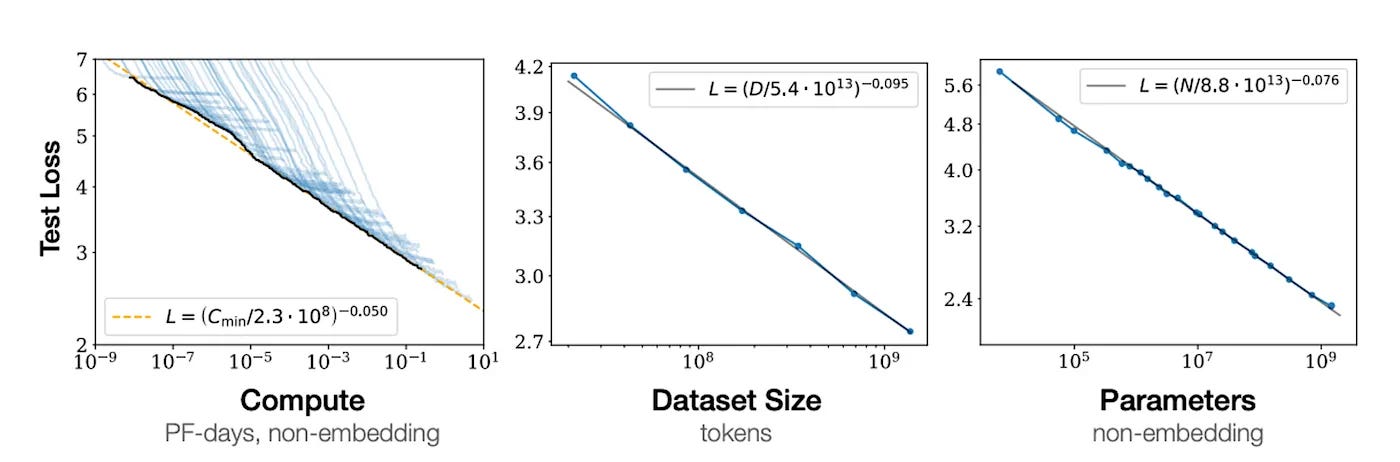
Caption: Figure of pre-training scaling laws.
The strongest argument for the near-term arrival of AGI was from the predictive power of pre-training scaling laws. The substantial performance gains from GPT-3 to GPT-3.5 and subsequently to GPT-4—achieved largely by increasing computational resources—were striking. This progression serves as strong evidence that scaling laws warrant serious consideration, as it demonstrates that expanding compute can indeed lead to greater intelligence.
And yet, it looks like pre-training scaling is starting to run out. GPT-4.5 is seen by many (but not all) as a disappointment. It certainly didn’t crush benchmarks as GPT-4 did on release, and improvements seem more marginal. Yes, you can decrease next-token prediction loss by scaling up your system, but the mapping from next-token prediction to raw smarts seems to be falling (although this is debatable, a point we will discuss more in a few weeks). This failure will significantly weaken companies’ appetite to train GPT-6 or 7-sized models.
The failure of pre-training has led many to state that there are other methods we can get to AGI including reinforcement learning (RL) on top, test time compute, and automating AI R&D. We will discuss all those possible routes in the rest of the article, but please notice that these are not the pre-registered predictions that were made a year ago (e.g. here) which focused on scaling pre-training. Moreover, they are far more speculative. We had a lot of empirical evidence on the returns to scaling pre-training, but we do not have that for these other categories. While these other paths could work, we do not have much evidence on these other paths to AGI other than vibes.
2. RL May not Work on Long-Time Horizons
Since scaling may start to fail, many of those with short timelines point to o1 reasoning styling models as a ‘new dimension to scale’. While, like many, we find o1/o3 extremely impressive, whether this will ‘scale to AGI’ easily on domains we actually care about (e.g. running a business, being a remote worker, etc) is still in question.
Reasoning models are trained via reinforcement learning (RL) on math and code. Because these settings have a simple verifier, models can learn quickly to produce more and more accurate answers. The mention of RL makes people think we can easily apply the same setup to any verifiable setting like business, trading, robots, etc. But, in fact, these cases could be much, much harder than math and code because they involve long-term actions and planning. The deep learning revolution has taught us that these systems work really well with a large amount of data. However, in these long-term tasks like running a business, you do not get a large amount of feedback data. You get these weak intermediate signals before the business either takes off or fails. Somehow, humans learn from these very weak signals to make decent decisions, but it is not a setting that is very amenable to RL systems.
To make this point, we will need to get into a bit of the weeds about what RL is because the RL training in recent reasoning models is barely RL at all. In a reasoning task, models simply take one action (outputting their answer) and then get a known/verifiable score. This contrasts with a true RL environment, where models take many actions and get intermediate feedback before getting some final score. The later environment is much harder because the model needs to balance exploration and exploitation, credit assignment, learning a reward model for the intermediate states, etc.
Simply speaking, if you take 1 action and then get told if it is good or bad, it’s very easy to update quickly to start taking good actions. But if you take 1000 actions before you are told if your end state is good or bad, it is very hard to tell if your first action was good or bad. To get AGI at the level of drop-in remote workers, we will have to get the true RL environment working, and so far that has remained elusive.
3. Not all Aspects of Test-Time Scaling Can be Scaled
When reasoning models like OpenAI’s o1 were first released, one of the major talking points was that it unlocked a new dimension we could scale —test-time compute. However, conversations on this are usually ambiguous. There are really two dimensions on which we can scale models in the reasoning model style. First, we can scale the number of reasoning examples. Second, we can scale how long models respond for. We are bullish on the first method of scaling but not the second.
The first dimension we could scale is just the number of training examples. We are bullish on this because you have more reasoning tricks you can learn. The original o1 let models learn basic reasoning patterns like “I think I made a mistake, let me go back” which led to downstream performance increases. We expect that more math examples will let you learn more of these tricks. People have already seen what these improvements look like in the progress of o1 to o3.
However, while we are bullish on this direction, we are somewhat skeptical that this will let us scale to AGI directly. First, we have quite a limited understanding of how far we can push out reasoning RL. We really have just two data points in o1 and o3. It’s plausible that we can scale it out further, but it’s not like we have good data to predict the trends accurately. Therefore, there exists a high degree of uncertainty about how far one can go in this paradigm. It might become superhuman very quickly, but it also might hit a wall. Second, we have seen fairly limited generalization from math/code to other tasks, so it is clear that reasoning RL is not alone sufficient to get us to AGI.
The second dimension is scaling up the length and attempts. However, in both categories, these are probably not the items we can scale directly. Take this now famous graph.

One common interpretation of this graph is that we can scale test-time compute (AI thinking for a longer time) to get higher accuracy in the same way we scaled train-time compute (training for a longer time). However, we think this interpretation is quite misleading as it confuses correlation for causation. In the train-time case, we had direct control over train-time compute and could scale it up by adding parameters, data, etc. The increase in this compute caused accuracy to go up. But the test-time case is different; test-time compute increasing did not cause accuracy to increase. Rather, RL on reasoning traces caused both test-time compute and accuracy to increase. RL increased both of these by teaching the model to use reasoning patterns like “let me check my work”, “I think I’ve made a mistake, let me go back”, etc. These reasoning patterns took more tokens, which increased compute usage at test-time but were also useful to get correct answers. But notice, the increased compute did not cause the accuracy to go up; it’s a byproduct of using more tokens for reasoning. This fact matters when we think about extrapolating these graphs out. If you have already learned all the reasoning patterns, there is no way to “scale” test-time compute up further that will get you more accuracy.
4. Automating AI R&D Does Not Necessary Cause a Self-Improvement Loop to AGI
Finally, the last frequently mentioned point for AGI soon is that AI systems are close to automating AI R&D, and this will cause systems to self-improve to AGI. Our core view is that automated AI R&D with coding agents, etc., will likely accelerate “normal” ML science where you run experiments, check benchmarks, etc. So, insofar as the path to AGI looks like normal ML science, we expect automated AI R&D to get us there a bit faster. However, the case for longer timelines we sketched out above relies on normal ML not getting us directly to AGI. If RL, scaling up pre-training, etc., do not get us to AGI, then we need a paradigmatic breakthrough on the order of neural networks, transformers, etc., to get there. Automated AI R&D may help a bit here as you can experiment faster, but that’s not really the binding constraint for paradigmatic breakthroughs. Therefore, automated AI R&D will be more of an acceleration on the already short timeline worlds where we know how to get to AGI via the above methods, but it will not have much effect in the worlds where timelines are long because LLMs are a dead-end to AGI.
Conclusion:
The progress of language models over the last 2-3 years has been shocking, and yet the effect has also been shockingly narrow. The raw intellect of the models seems extremely high at first glance, but even basic computer use is taking longer than expected. The path to AGI could feel similar. We might get blazing smart models on Q&A formats, but when it comes to automating significant shares of human labor, it might take a surprisingly long time.
 | A guest post by
|
nice post! I shared it with metrics folks as: "omitted variable bias in the test-time compute scaling law"